Lately a couple people have asked me about how much swap space is “right” for their servers – especially in the context of running low spec machines like AWS t2.nano/t2.micro or Digital Ocean boxes with low allocations like 1GB or 512MB RAM.
The old fashioned advice was always “your swap space should be double your RAM” but this doesn’t actually make a lot of sense any more. Really swap should be considered a tool of last resort – a hack even – to squeeze a bit more performance out of systems and should be used sparingly where it makes sense.
I tend to look after two different types of systems:
- Small systems running a specific dedicated service (eg microservices). These systems might do nothing more than run Nginx/Apache or something like PHP-FPM or Unicorn with a few workers. They typically have 512MB-1GB of RAM.
- Big heavy servers running heavy weight applications, typically Java. These systems will be configured with large memory allocations (eg 16GB) and be configured to allocate a specific amount of memory to the application (eg 10GB Java Heap) and to keep the rest free for disk cache and background apps.
The latter doesn’t need swap. There’s no time I would ever want my massive apps getting pushed into swap for a couple reasons:
- Performance of these systems is critical. We’ve paid good money to allocate them specific amounts of memory which is essentially guaranteed – we know how much the heap needs, how much disk cache we need and how much to allocate to the background apps.
- If something does go wrong and starts consuming too much RAM, rather than having performance degrade as the server tries to swap, I want it to die – and die fast. If Puppet has decided it wants 7 GB of RAM, I want the OOM to step in and slaughter it. If I have swap, I risk everything on the server being slowed down as it moves tasks into the horribly slow (even on SSD) swap space.
- If you’re paying for 16GB of RAM, why do you want to try and get an extra 512MB out of some swap space? It’s false economy.
For this reason, our big boxes are all swapless. But what about the former example, the small microservice type boxes, or your small personal VPS type systems?
Like many things in IT, “it depends”.
If you’re running stateless clusters, provided that the peak usage fits within the memory allocation, you don’t need swap. In this scenario, your workload is sized appropriately and if anything goes wrong due to an unexpected issue, the machine will either kill the errant process or die and get removed from the pool entirely.
I run a lot of web app workers this way – for example a 1GB t2.micro can happily run 4 Ruby Unicorn workers averaging around 128MB each, plus have space for Puppet, monitoring and delayed jobs. If something goes astray, the process gets killed and the usual automated recovery processes handle things.
However you may need some swap if you’re running stateful systems (pets) where it’s better for them to go slow than to die entirely, or if you’re running a system where the peak usage won’t fit within the memory allocation due to tight budget constraints.
For an example of tight budget constraints – I run this blog on a small machine with only 512MB RAM. With an allocation this small, there’s just not enough memory to run applications like Apache and also be able to handle the needs of background daemons and Puppet runs which can use several hundred MB just by themselves.
The approach I took was to create a small swap volume and size the worker counts in Apache so that the max workers at average size would just fit within the real memory allocation. However any background or system tasks, would have to fight over the swap space.
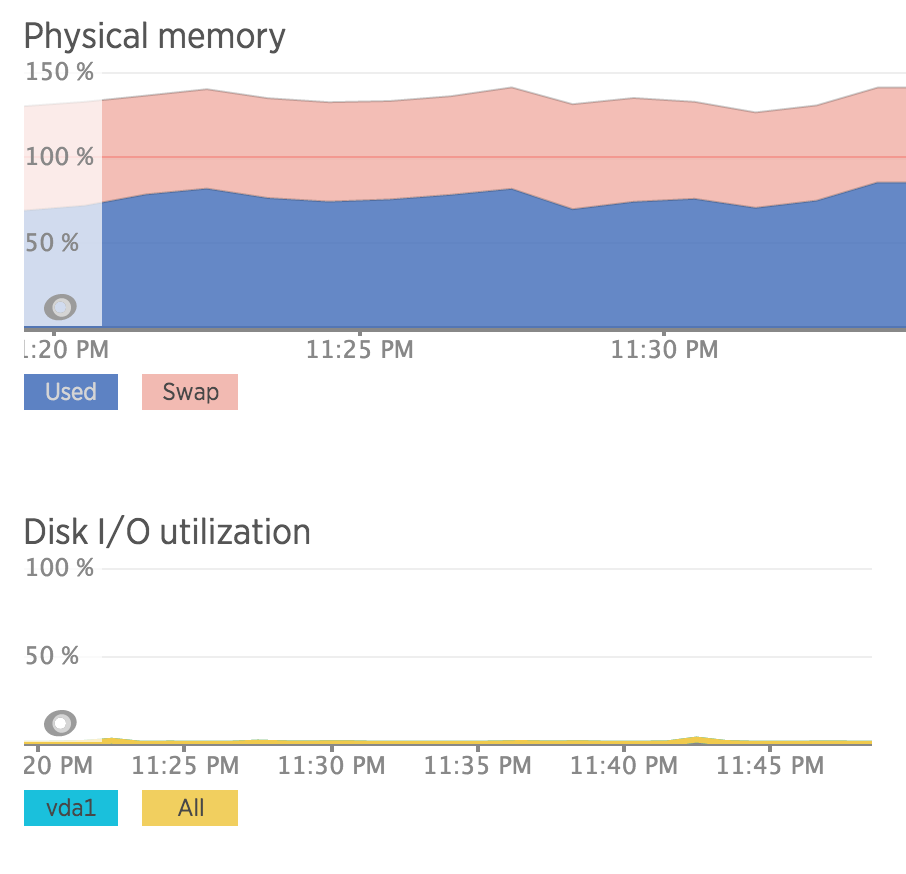
What you can see from the above is that I’m consuming quite a bit of swap – but my disk I/O is basically nothing. That’s because most of what’s in swap on this machine isn’t needed regularly and the active workload, i.e. the apps actually using/freeing RAM constantly, fit within the available amount of real memory.
In this case, using swap allows me to get better value for money, than using the next size up machine – I’m paying just enough to run Apache and squeezing in the management tools and background jobs onto the otherwise underutilized SSD storage. This means I can spend $5 to run this blog, vs $10. Excellent!
In respects to sizing, I’m running with a 1GB swap on a 512MB RAM server which is compliant with the traditional “twice your RAM” approach to sizing. That being said, I wouldn’t extend past this, even if the system had more RAM (eg 2GB) you should only ever use swap as a hack to squeeze a bit more out of a system. Basically don’t assume swap will scale linearly as memory scales.
Given I’m running on various cloud/VPS environments, I don’t have a traditional swap partition – instead I create an image file on the root filesystem and format it as swap space – I use a third party Puppet module (https://forge.puppetlabs.com/petems/swap_file) to do this:
swap_file::files { 'default':
ensure => present,
swapfile => '/tmp/swapfile',
swapfilesize => '1000 MB’
}
The performance impact of using a swap file ontop of a filesystem is almost nothing and this dramatically simplifies management and allocation of swap space. Just make sure you’re not using tmpfs for that /tmp path or you’ll find that memory benefit isn’t as good as it seems.