I’ve been learning a bit of Swift lately in order to write an iOS app for my alarm system. I’m not very good at it yet, but figured I’d write some notes to help anyone else playing with the murky world of Firebase Cloud Messaging/FCM and iOS.
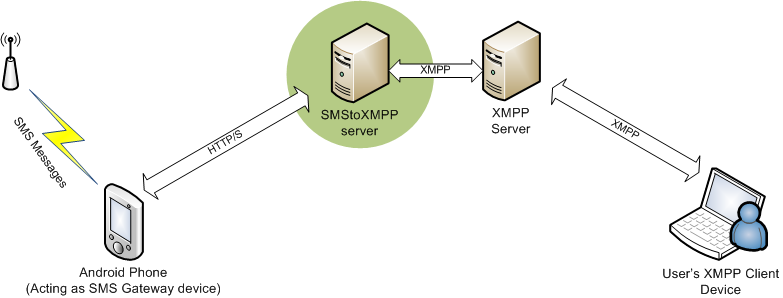
One of the key parts of the design is that I wanted the alarm app and the alarm server to communicate directly with each other without needing public facing endpoints, rather than the conventional design when the app interacts via an HTTP API.
The intention of this design is that it means I can dump all the alarm software onto a small embedded computer and as long as that computer has outbound internet access, it just works™️. No headaches about discovering the endpoint of the service and much more simplified security as there’s no public-facing web server.
Given I need to deliver push notifications to the app, I implemented Google Firebase Cloud Messaging (FCM) – formerly GCM – for push delivery to both iOS and Android apps.
Whilst FCM is commonly used for pushing to devices, it also supports pushing messages back upstream to the server from the device. In order to do this, the server must be implemented as an XMPP server and the FCM SDK be embedded into the app.
The server was reasonably straight forwards, I’ve written a small Java daemon that uses a reference XMPP client implementation and wraps some additional logic to work with HowAlarming.
The client side was a bit more tricky. Google has some docs covering how to implement upstream messaging in the iOS app, but I had a few issues to solve that weren’t clearly detailed there.
Handling failure of FCM upstream message delivery
Firstly, it’s important to have some logic in place to handle/report back if a message can not be sent upstream – otherwise you have no way to tell if it’s worked. To do this in swift, I added a notification observer for .MessagingSendError which is thrown by the FCM SDK if it’s unable to send upstream.
class AppDelegate: UIResponder, UIApplicationDelegate, MessagingDelegate {
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
...
// Trigger if we fail to send a message upstream for any reason.
NotificationCenter.default.addObserver(self, selector: #selector(onMessagingUpstreamFailure(_:)), name: .MessagingSendError, object: nil)
...
}
@objc
func onMessagingUpstreamFailure(_ notification: Notification) {
// FCM tends not to give us any kind of useful message here, but
// at least we now know it failed for when we start debugging it.
print("A failure occurred when attempting to send a message upstream via FCM")
}
}
Unfortunately I’m yet to see a useful error code back from FCM in response to any failures to send message upstream – seem to just get back a 501 error to anything that has gone wrong which isn’t overly helpful… especially since in web programming land, any 5xx series error implies it’s the remote server’s fault rather than the client’s.
Getting the GCM Sender ID
In order to send messages upstream, you need the GCM Sender ID. This is available in the GoogleService-Info.plist file that is included in the app build, but I couldn’t figure out a way to extract this easily from the FCM SDK. There probably is a better/nice way of doing this, but the following hack works:
// Here we are extracting out the GCM SENDER ID from the Google
// plist file. There used to be an easy way to get this with GCM, but
// it's non-obvious with FCM so here's a hacky approach instead.
if let path = Bundle.main.path(forResource: "GoogleService-Info", ofType: "plist") {
let dictRoot = NSDictionary(contentsOfFile: path)
if let dict = dictRoot {
if let gcmSenderId = dict["GCM_SENDER_ID"] as? String {
self.gcmSenderId = gcmSenderId // make available on AppDelegate to whole app
}
}
}
And yes, although we’re all about FCM now, this part hasn’t been rebranded from the old GCM product, so enjoy having yet another acronym in your app.
Ensuring the FCM direct channel is established
Finally the biggest cause I had for upstream message delivery failing, is that I was often trying to send an upstream message before FCM had finished establishing the direct channel.
This happens for you automatically by the SDK whenever the app is loaded into foreground, provided that you have shouldEstablishDirectChannel set to true. This can take up to several seconds after application launch for it to actually complete – which means if you try to send upstream too early, the connection isn’t ready, and your send fails with an obscure 501 error.
The best solution I found was to use an observer to listen to .MessagingConnectionStateChanged which is triggered whenever the FCM direct channel connects or disconnects. By listening to this notification, you know when FCM is ready and capable of delivering upstream messages.
An additional bonus of this observer, is that when it indicates the FCM direct channel is established, by that time the FCM token for the device is available to your app to use if needed.
So my approach is to:
- Setup FCM with
shouldEstablishDirectChannelset totrue(otherwise you won’t be going upstream at all!). - Setup an observer on
.MessagingConnectionStateChanged - When triggered, use
Messaging.messaging().isDirectChannelEstablishedto see if we have a connection ready for us to use. - If so, pull the FCM token (device token) and the GCM Sender ID and retain in
AppDelegatefor other parts of the app to use at any point. - Dispatch the message to upstream with whatever you want in
messageData.
My implementation looks a bit like this:
class AppDelegate: UIResponder, UIApplicationDelegate, MessagingDelegate {
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
...
// Configure FCM and other Firebase APIs with a single call.
FirebaseApp.configure()
// Setup FCM messaging
Messaging.messaging().delegate = self
Messaging.messaging().shouldEstablishDirectChannel = true
// Trigger when FCM establishes it's direct connection. We want to know this to avoid race conditions where we
// try to post upstream messages before the direct connection is ready... which kind of sucks.
NotificationCenter.default.addObserver(self, selector: #selector(onMessagingDirectChannelStateChanged(_:)), name: .MessagingConnectionStateChanged, object: nil)
...
}
@objc
func onMessagingDirectChannelStateChanged(_ notification: Notification) {
// This is our own function listen for the direct connection to be established.
print("Is FCM Direct Channel Established: \(Messaging.messaging().isDirectChannelEstablished)")
if (Messaging.messaging().isDirectChannelEstablished) {
// Set the FCM token. Given that a direct channel has been established, it kind of implies that this
// must be available to us..
if self.registrationToken == nil {
if let fcmToken = Messaging.messaging().fcmToken {
self.registrationToken = fcmToken
print("Firebase registration token: \(fcmToken)")
}
}
// Here we are extracting out the GCM SENDER ID from the Google PList file. There used to be an easy way
// to get this with GCM, but it's non-obvious with FCM so we're just going to read the plist file.
if let path = Bundle.main.path(forResource: "GoogleService-Info", ofType: "plist") {
let dictRoot = NSDictionary(contentsOfFile: path)
if let dict = dictRoot {
if let gcmSenderId = dict["GCM_SENDER_ID"] as? String {
self.gcmSenderID = gcmSenderId
}
}
}
// Send an upstream message
let messageId = ProcessInfo().globallyUniqueString
let messageData: [String: String] = [
"registration_token": self.registrationToken!, // In my use case, I want to know which device sent us the message
"marco": "polo"
]
let messageTo: String = self.gcmSenderID! + "@gcm.googleapis.com"
let ttl: Int64 = 0 // Seconds. 0 means "do immediately or throw away"
print("Sending message to FCM server: \(messageTo)")
Messaging.messaging().sendMessage(messageData, to: messageTo, withMessageID: messageId, timeToLive: ttl)
}
}
...
}
For a full FCM downstream and upstream implementation example, you can take a look at the HowAlarming iOS app source code on Github and if you need a server reference, take a look at the HowAlarming GCM server in Java.
Learnings
It’s been an interesting exercise – I wouldn’t particularly recommend this architecture for anyone building real world apps, the main headaches I ran into were:
- FCM SDK just seems a bit buggy. I had a lot of trouble with the GCM SDK and the move to FCM did improve stuff a bit, but there’s still a number of issues that occur from time to time. For example: occasionally a FCM Direct Channel isn’t established for no clear reason until the app is terminated and restarted.
- Needing to do things like making sure FCM Direct Channel is ready before sending upstream messages should probably be handled transparently by the SDK rather than by the app developer.
- I have still yet to get background code execution on notifications working properly. I get the push notification without a problem, but seem to be unable to trigger my app to execute code even with
content-available == 1. Maybe a bug in my code, or FCM might be complicating the mix in some way, vs using pure APNS. Probably my code. - It’s tricky using FCM messages alone to populate the app data, occasionally have issues such as messages arriving out of order, not arriving at all, or occasionally ending up with duplicates. This requires the app code to process, sort and re-populate the table view controller which isn’t a lot of fun. I suspect it would be a lot easier to simply re-populate the view controller on load from an HTTP endpoint and simply use FCM messages to trigger refreshes of the data if the user taps on a notification.
So my view for other projects in future would be to use FCM purely for server->app message delivery (ie: “tell the user there’s a reason to open the app”) and then rely entirely on a classic app client and HTTP API model for all further interactions back to the server.