In a twist of irony, shortly after boarding my flight in Sydney for my trip back to Wellington to escape the heat of the AU summer, my home NZ server crashed due to the massive 30 degree heatwave experienced in Wellington on Christmas day. :-/
I have two NZ servers, my public facing colocation host, and my “home” server which now lives at my parent’s house following my move. The colocation box is nice and comfy in it’s aircon controlled climate, but the home server fluctuates quite significantly thanks to the Wellington climate and it’s geolocation of being in a house rather than a more temperature consistent apartment/office.
After bringing the host back online, Munin showed some pretty scary looking graphs:
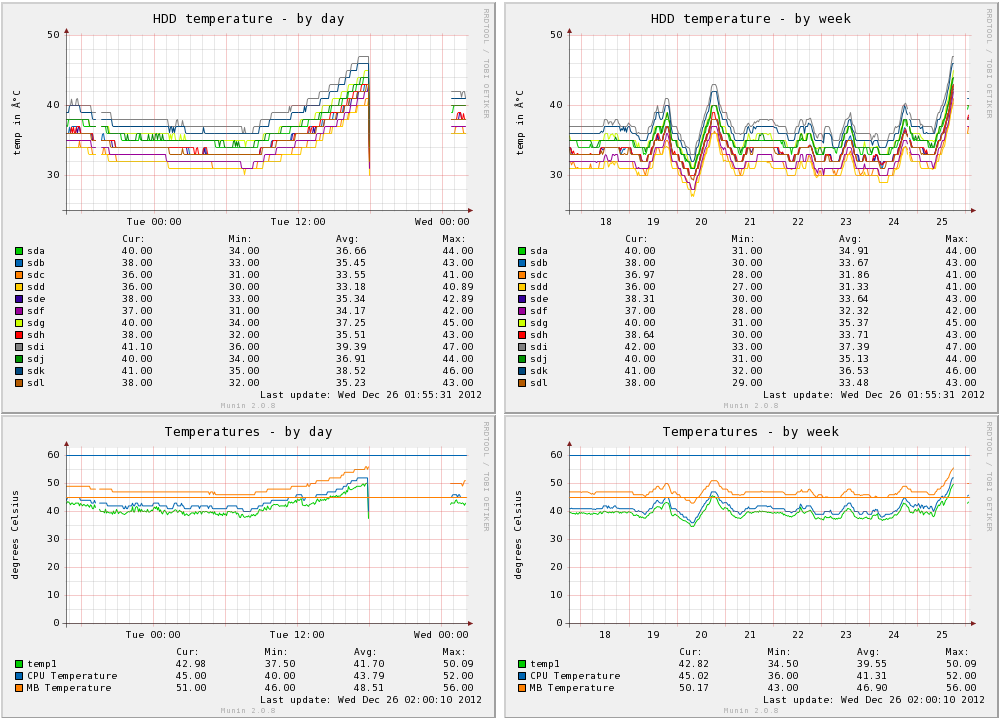
localhost flew too close to the sun and plummeted to his doom
I’ve had problems with the stability of this system in the past. Whilst I mostly resolved this with the upgrades in cooling, there are still the odd occasions of crashing, which appears to be linked with summer months.
The above graphs are interesting since they show a huge climb in disk temperatures, although I still suspect it’s the CPU that lead to the actual system crash occurring – the CPU temperature graphs show a climb up towards 60 degrees, which is the level where I’ve seen many system crashes in the past.
What’s particularly annoying is that all these crashes cause the RAID 6 to trigger a rebuild – I’m unsure as to why exactly this is, I suspect that maybe the CPU hangs in the middle of a disk operation that has written to some disks, but not all.
Having the RAID rebuild after reboot is particularly nasty since it places even more load and effort onto an already overheated system and subjects the array to increased failure risk due to the loss of redundancy. I’d personally consider this a kernel bug, if a disk operation failed, the array should still have a known good state and be able to recover from that – fail only the blocks that are borked.
Other than buying less iffy hardware and finding a cooler spot in the house, there’s not a lot else I can do for this box…. I’m pondering using CPU frequency scaling to help reduce the temperature, by dropping the clock speed of the CPU if it gets too hot, but that has it’s own set of risks and issues associated with it.
In past experiments with temperature scaling on this host, it hasn’t worked too well with the high virtualised workload causing it to swap frequently between high and low performance, leading to an increase in latency and general sluggishness on the host. There’s also a risk that clocking down the CPU may just result in the same work taking longer on the CPU potentially still generating a lot of heat.
I could attack the workload somewhat, the VMs on the host are named based on their role, eg (prod-, devel-, dr-) so there’s the option to make use of KVM to suspend all but key production VMs when the temperature gets too high. Further VM type tagging would help target this a bit more, for example my minecraft VM is a production host, but it’s less important than my file server VM and could be suspended on that basis.
Fundamentally the host staying online outweighs the importance of any of the workloads, on the simple basis that if the host is still online, it can restart services when needed. If the host is down, then all services are broken until human intervention can be provided.